ICLR 2026|新版「图灵测试」:当VLA走进生物实验室
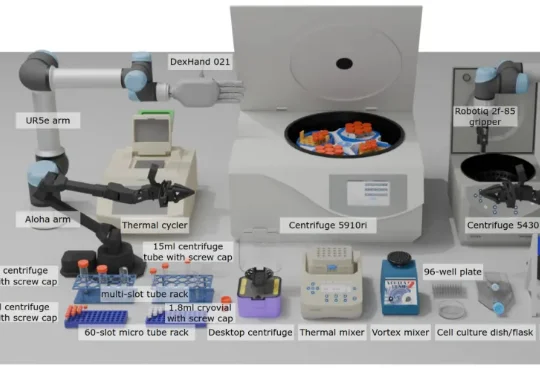
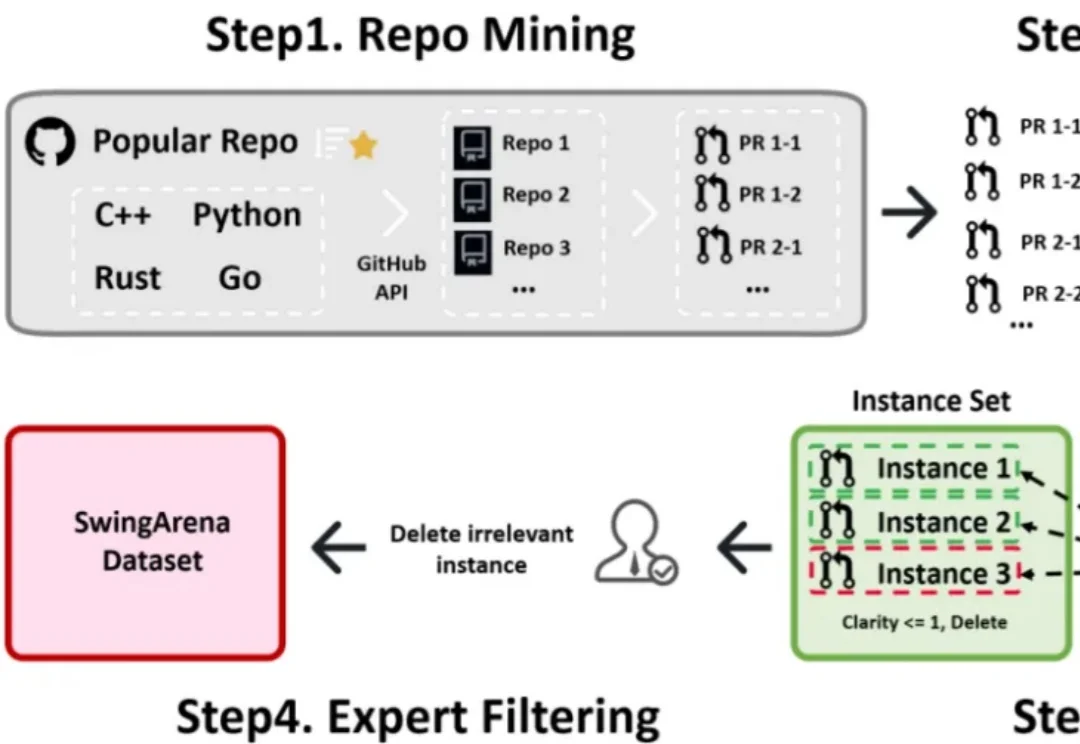
ICLR 2026|新版「图灵测试」:当VLA走进生物实验室现有 VLA 模型的研究和基准测试多局限于家庭场景(如整理餐桌、折叠衣物),缺乏对专业科学场景(尤其是生物实验室)的适配。生物实验室具有实验流程结构化、操作精度要求高、多模态交互复杂(透明容器、数字界面)等特点,是评估 VLA 模型精准操作、视觉推理和指令遵循能力的理想场景之一。
来自主题: AI技术研报
7760 点击 2026-02-20 13:00
 搜索
搜索
现有 VLA 模型的研究和基准测试多局限于家庭场景(如整理餐桌、折叠衣物),缺乏对专业科学场景(尤其是生物实验室)的适配。生物实验室具有实验流程结构化、操作精度要求高、多模态交互复杂(透明容器、数字界面)等特点,是评估 VLA 模型精准操作、视觉推理和指令遵循能力的理想场景之一。
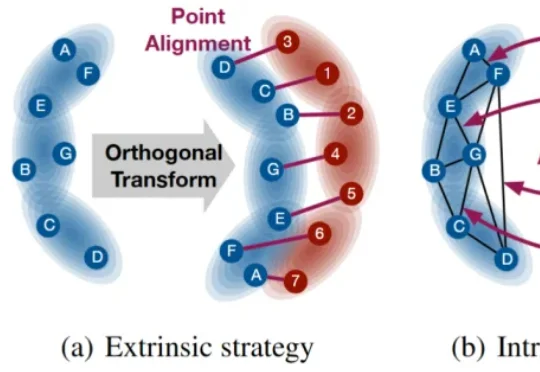
本文提出一种具有 SE(p) 不变传输性质的度量 SEINT:通过构造无需训练的 SE(p) 不变表示,将高维结构信息压缩为可用于 Optimal Transport (OT) 对齐的一维表征,从而在保持不变性与严格度量性质的同时显著提升效率。
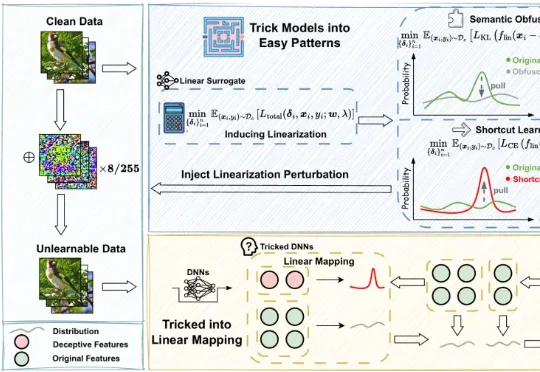
不可学习样本(Unlearnable Examples)是一类用于数据保护的技术,其核心思想是在原始数据中注入人类难以察觉的微小扰动,使得未经授权的第三方在使用这些数据训练模型时,模型的泛化性能显著下降,甚至接近随机猜测,从而达到阻止数据被滥用的目的。
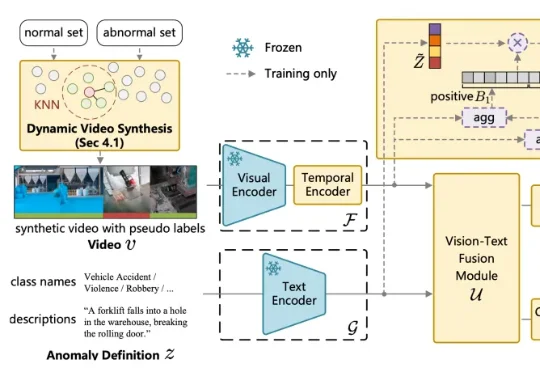
针对这一问题,中国传媒大学媒体融合与传播国家重点实验室的吴晓雨教授团队于 ICLR 2026 发表论文《Language-guided Open-world Video Anomaly Detection under Weak Supervision》,直面 VAD 领域的核心问题 —— 什么是异常?

DiscoX构建了一套200题的长文翻译数据集,以平均长度1,712 tokens的长篇章做评测单元,要求整个长文文本作为一个整体来翻译,除翻译准确度外,重点考察跨段落的逻辑与风格一致性、上下文中的术语精确性、以及专业写作规范,贴合用户真实的使用场景。
过去一年,大模型写代码的能力几乎以肉眼可见的速度提升。从简单脚本到完整功能模块,GPT、Claude、DeepSeek 等模型已经能够在几秒钟内生成看起来相当 “专业” 的代码。
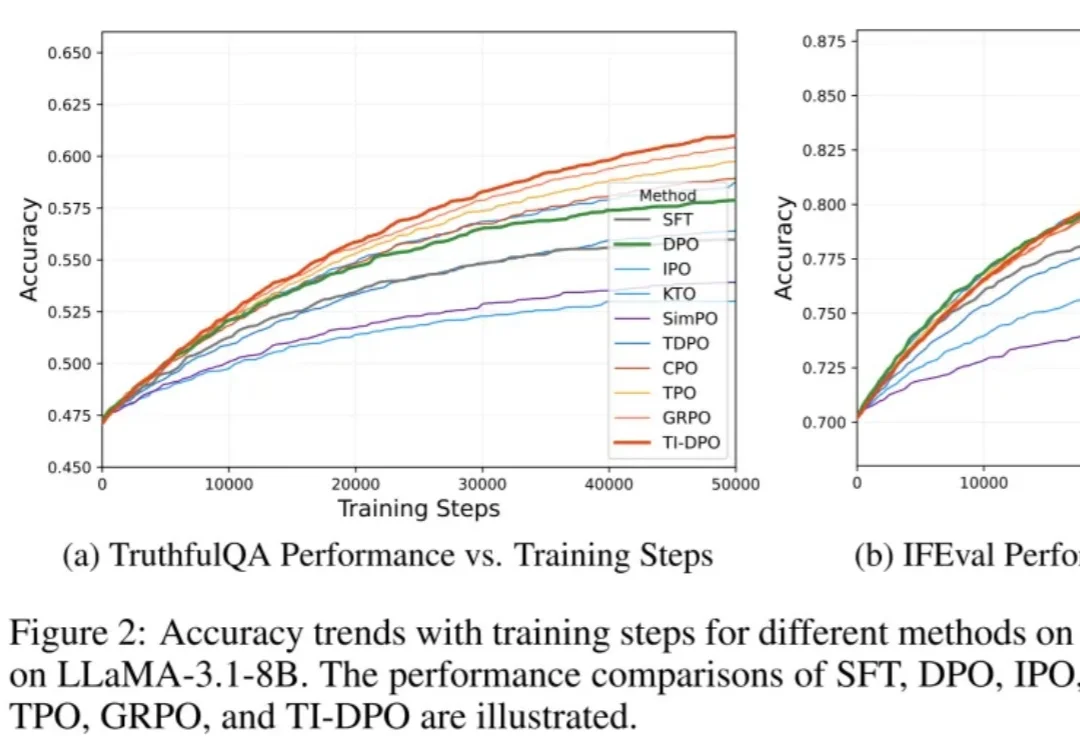
在当今的大模型后训练(Post-training)阶段,DPO(直接偏好优化) 凭借其无需训练独立 Reward Model 的优雅设计和高效性,成功取代 PPO 成为业界的 「版本之子」,被广泛应用于 Llama-3、Mistral 等顶流开源模型的对齐中。
本⽂的主要作者来⾃上海交通⼤学和上海⼈⼯智能实验室,核⼼贡献者包括任麒冰、郑志杰、郭嘉轩,指导⽼师为⻢利庄⽼师和邵婧⽼师,研究⽅向为安全可控⼤模型和智能体。 最近,Moltbook 的爆⽕与随后的迅速

目前,人形机器人已经能在现实中跳舞、奔跑、甚至完成后空翻。但接下来更关键的问题是:这些系统能否在部署之后持续地进行强化学习 —— 在真实世界的反馈中变得更稳定、更可靠,并在分布不断变化的新环境里持续适应与改进?

2025 年 1 月 20 日,DeepSeek 发布了推理大模型 DeepSeek-R1,在学术界和工业界引发了对大模型强化学习方法的广泛关注与研究热潮。 研究者发现,在数学推理等具有明确答案的任务